

Plongée au cœur des modèles de langue : les LLM
Les modèles de langage de grande taille, ou Large Language Models (LLM), sont une branche de l’intelligence artificielle (IA) spécialisée dans le traitement et la génération de texte. Ils reposent sur des algorithmes d’apprentissage profond capables de «comprendre» et produire du langage naturel, comme si nous discutions avec un être humain.
Ainsi, ces LLM traduisent les mots en chiffres grâce à une technique appelée le word embedding. Mikolov et al. [1], à l’origine de Word2Vec, expliquent que « les mots apparaissant dans un contexte similaire ont des représentations vectorielles proches ». Ainsi, chaque mot est transformé en un vecteur numérique dans un espace à plusieurs dimensions. Cette représentation permet aux LLM de capturer les relations entre les mots. Par exemple, dans cet espace, les mots « dentiste » et « patient » seront plus proches l’un de l’autre que « dentiste » et les mots « football » ou « barbecue ». Imaginez un graphique où chaque mot est un point positionné selon sa signification. Les mots appartenant à une même catégorie, comme « extraction » ou « traitement endodontique », seront regroupés. Cette approche permet au modèle de comprendre que des mots proches dans cet espace partagent souvent un sens ou un contexte similaire (fig. 1).
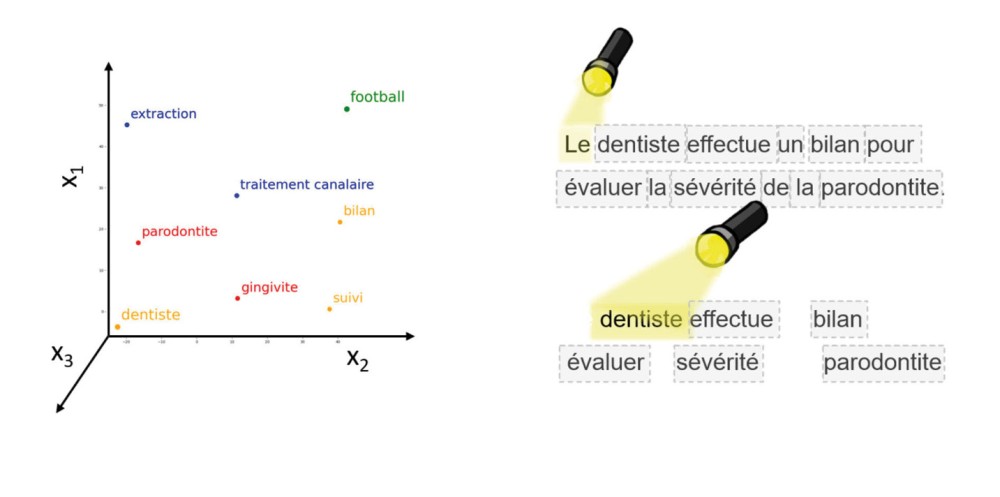
Une fois les mots représentés par des vecteurs, les LLM appliquent un autre concept clé : le mécanisme d’attention. Comme le soulignent Vaswani et al. [2] dans leur article fondateur sur les Transformers, « Attention is all you need », ces modèles exploitent des mécanismes d’auto-attention pour traiter efficacement les relations entre les mots dans une séquence.
Ce mécanisme permet au modèle de se concentrer sur les mots les plus pertinents dans une phrase ou un paragraphe. Par exemple, dans la phrase « Le dentiste effectue un bilan pour évaluer la…





